usedCarDatabase
Linear Regression Price Prediction
Project maintained by celikmustafa89 Hosted on GitHub Pages — Theme by mattgraham
USED CAR PRICE PREDICTION using LINEAR REGRESSION
1. DATASET
1. dateCrawled : when this ad was first crawled, all field-values are
taken from this date
2. name : "name" of the car
3. seller : private or dealer
4. offerType : the selling type of the car
5. price : the price on the ad to sell the car
6. abtest : unknown
7. vehicleType : type of the car. Limousine, kleinwagen, kombi, bus
etc.
8. yearOfRegistration : at which year the car was first
registered
9. gearbox : manuel or otomatic
10. powerPS : power of the car in PS
11. model : model of the car
12. kilometer : how many kilometers the car has driven
13. monthOfRegistration : at which month the car was first registered
14. fuelType : benzin, diesel, lpg etc
15. brand : brand of the car. Mercedes, Porsche, audi etc…
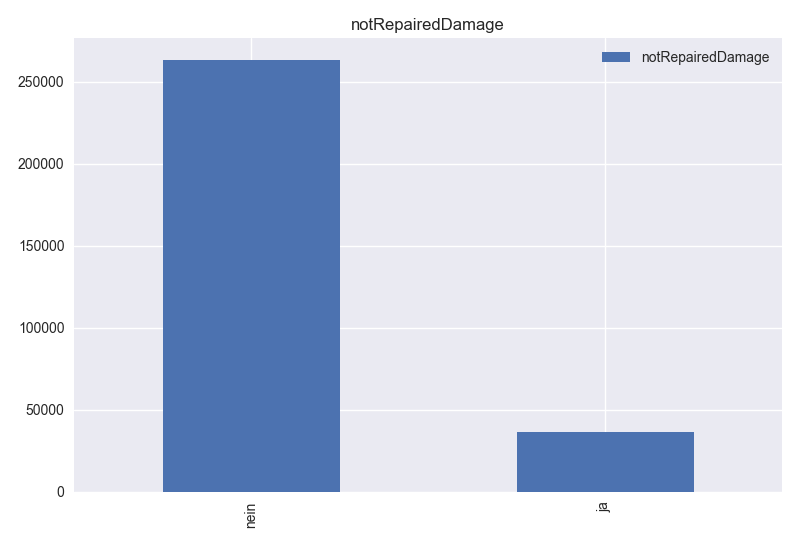
16. notRepairedDamage : if the car has a damage which is not repaired
yet. Yes or no
17. dateCreated : the date for which the ad at ebay was created
18. nrOfPictures : number of pictures in the ad
19. postalCode : code that shows the location of the car
20. lastSeenOnline : when the crawler saw this ad last online
2. DATA EXPLORATION
Dataset consists of 371528 rows and 20 columns [dateCrawled, name, seller, offerType, price, abtest, vehicleType, yearOfRegistration, gearbox, powerPS, model, kilometer, monthOfRegistration, fuelType, brand, notRepairedDamage, dateCreated, nrOfPictures, postalCode, lastSeen].
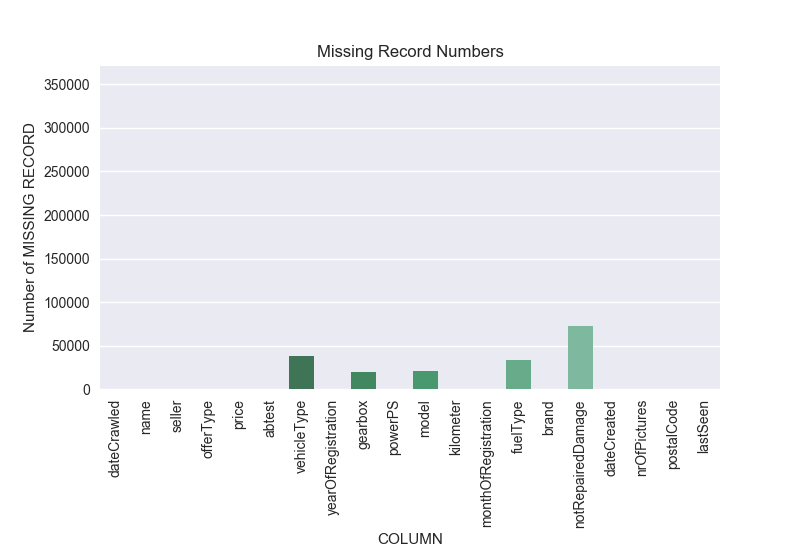
Figure 1: Missing Value
According to Figure 1:
- 5 columns [vehicleType, gearbox, model, fuelType, notRepairedDamage] have missing values. Depending on the model, these columns can be removed completely. However, these columns could be important for the model. So, the records that have null values can be removed. By removing the null values column can be saved for the model. In the table, notRepairedDamage column has 72060 missing value which is the 19% of the whole dataset. In this case, removing each record is not the best option. It seems better to drop whole column.
- In the whole dataset, 110572 records has at least one missing value. Removing these records are not the best option because it causes 33% data loss. So, data loss can be decreased by dropping some non-important columns or a representing value can be assigned the missing values.
According to Table 1 and the Histogram Graph of the columns:
- dateCrawled (280500), name (233531), lastSeen (182806) columns have too many unique values. Depending on the learning model, these columns can be dropped.
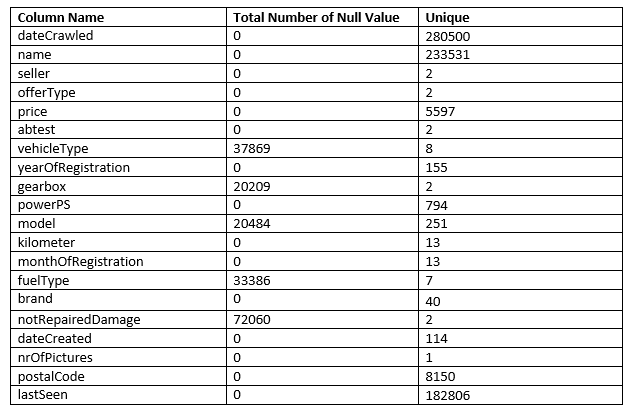
- Histogram of nrOfPictures column and Table 1 says that this column has only one values and it has no meaning for model and visualization. This column can be dropped.
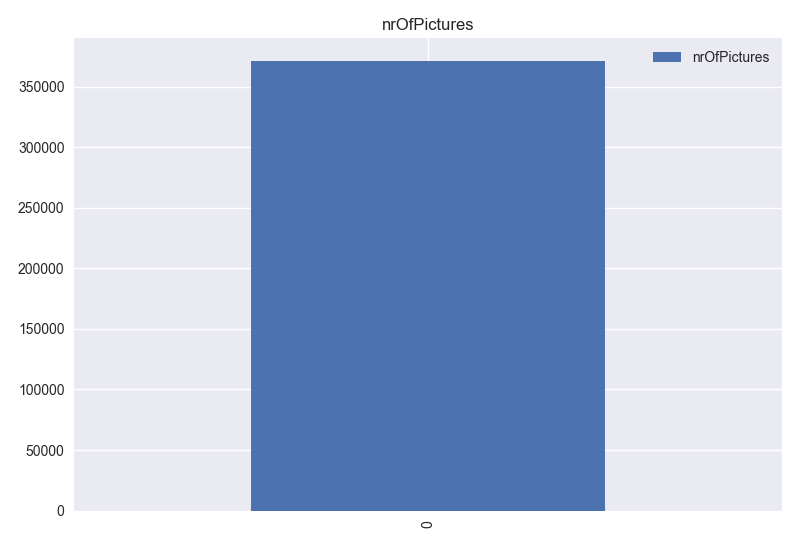
- Histogram graph of seller column and Table 1 says that this column has 2 unique values and “gewerblich” value has only 3 records. So, this column has no distinguishing information for the model. This column can be dropped, but first the records that has “gewerblich” value should be removed.
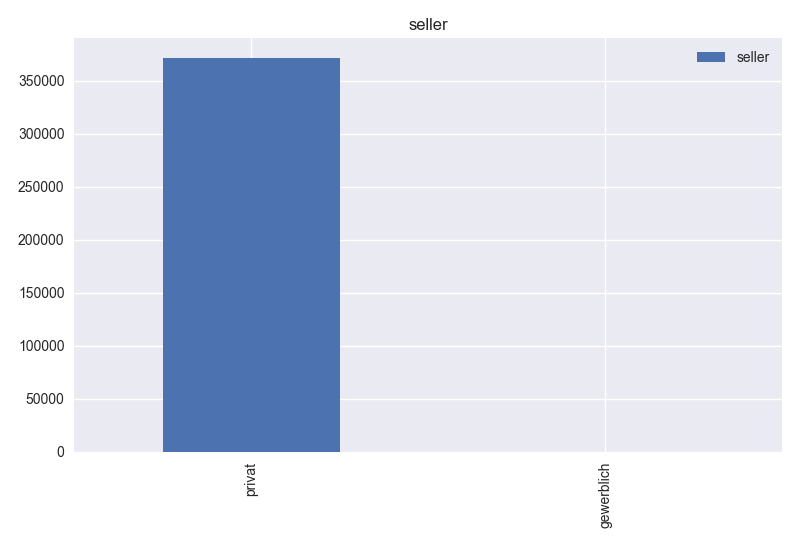
- Based on histogram graph of offerType, Table 1 and column description, this column has 2 unique values. “gesuch” value has only 12 records. So, this column has no distinguishing information for the model. This column can be dropped, after removing the records that has “gesuch” value.
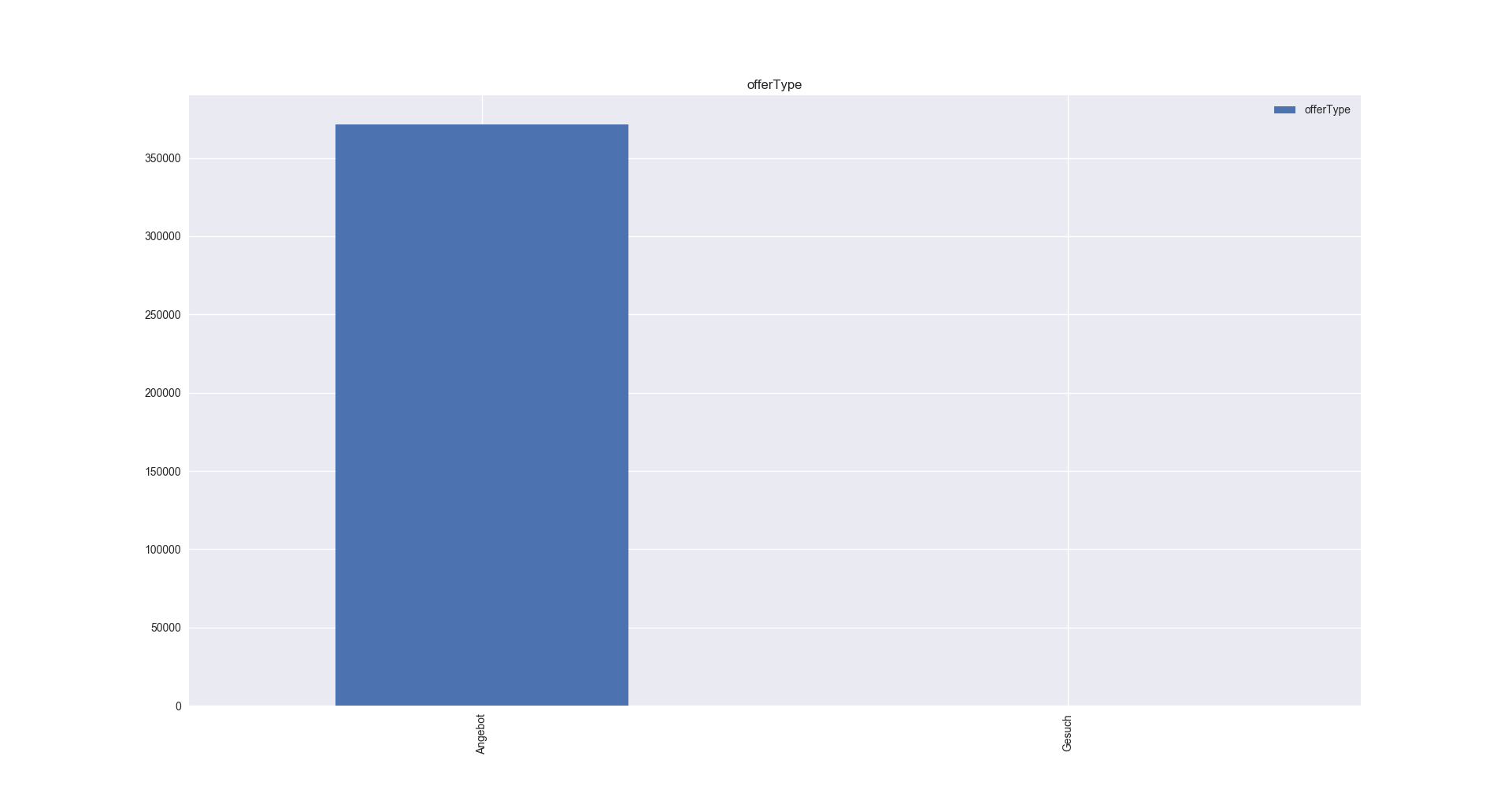
- Based on histogram graph of abtest and Table 1, this column has consistent values for the model.
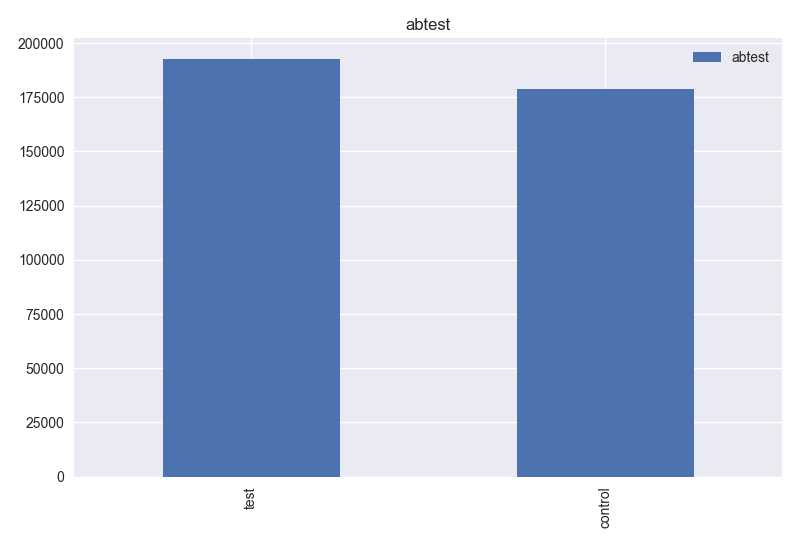
- Based on histogram graph of monthOfRegistration and Table 1, this column should have 12 unique values. However, it has 13 values. Also, dataset has yearOfRegistration column. So, this column can be dropped.
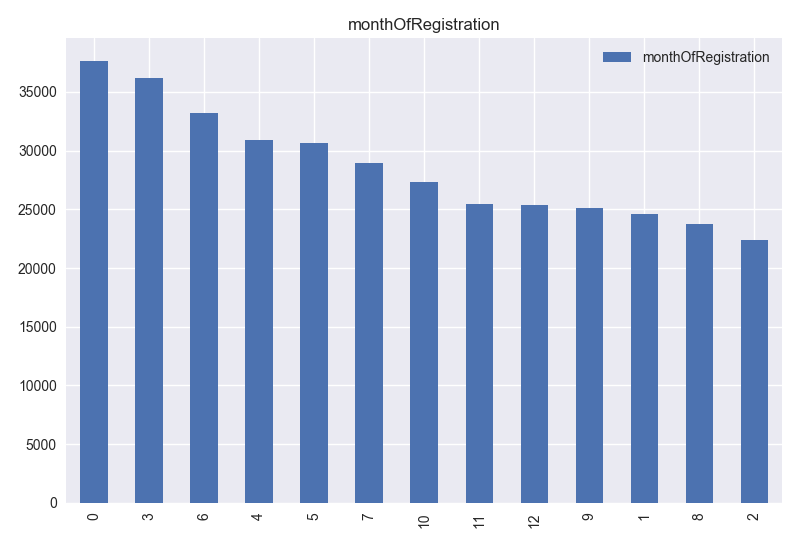
- postalCode column has 8150 unique values. This information can be used to determine the location of the car. However, for the model, location is not a distinguishing information because all car has postal code in Germany. Car location does not affect the model. This column can be dropped.
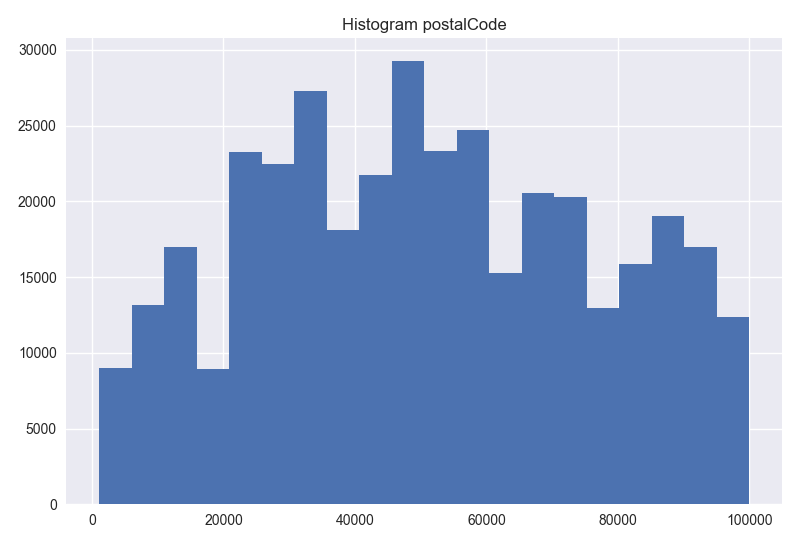
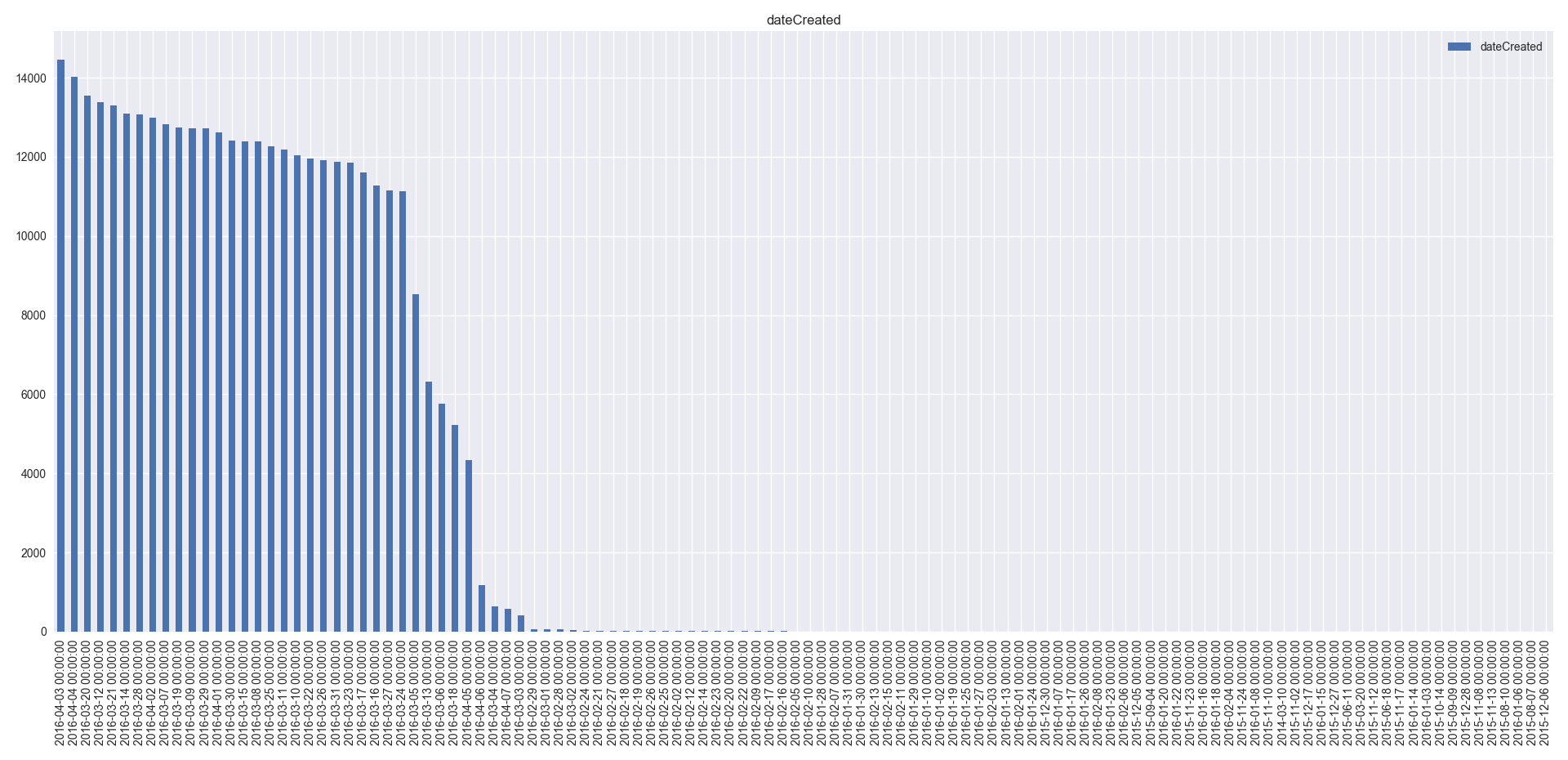
- dateCreated column has 114 unique values. This column has no distinguishing information for the model. So, this column can be dropped
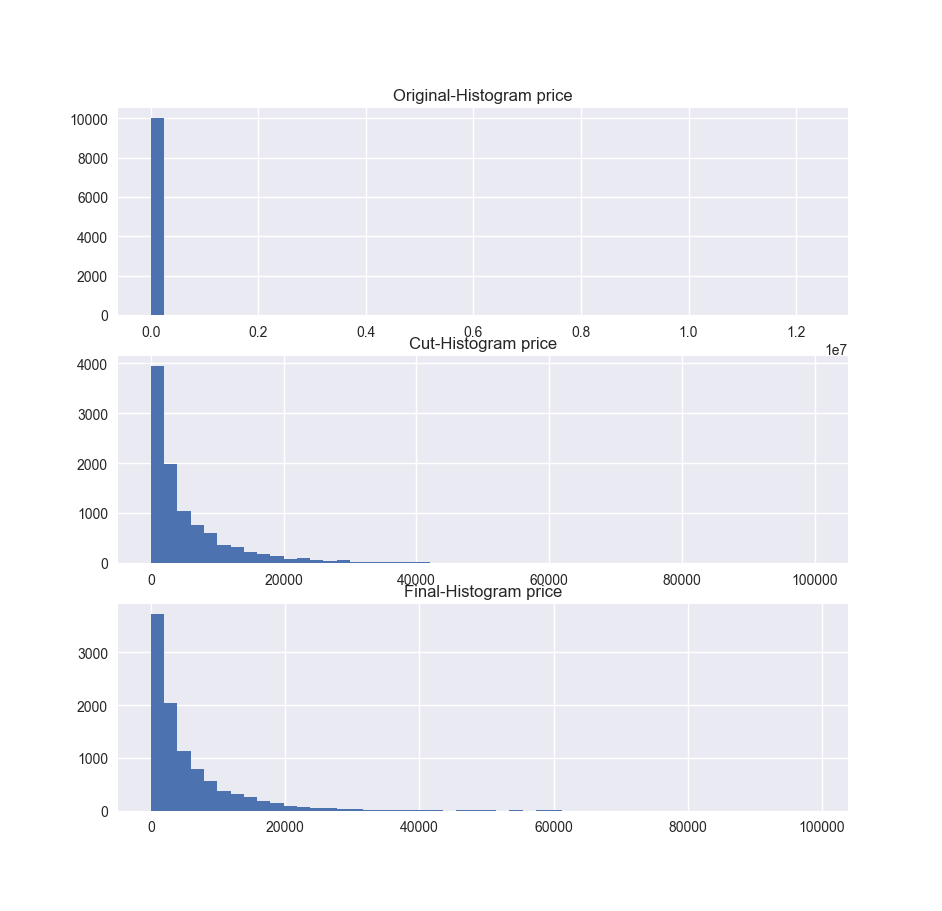
- Based on histogram of price column and its description, this column has 10772 records that has 0 value which means the car is free. Also, records have some value more than 100000 euro. It is not a consistent variable because cars can’t be that much expensive. To make dataset more consistent, prices values which are 0 and larger than 100000 can be removed. The histogram graph of price column are below. First graph shows the original distribution of the prices. Second graph shows the prices without free cars. Third graph shows the prices between 0 and 100000 euro. Other records can be removed from the dataset to have consistent values.
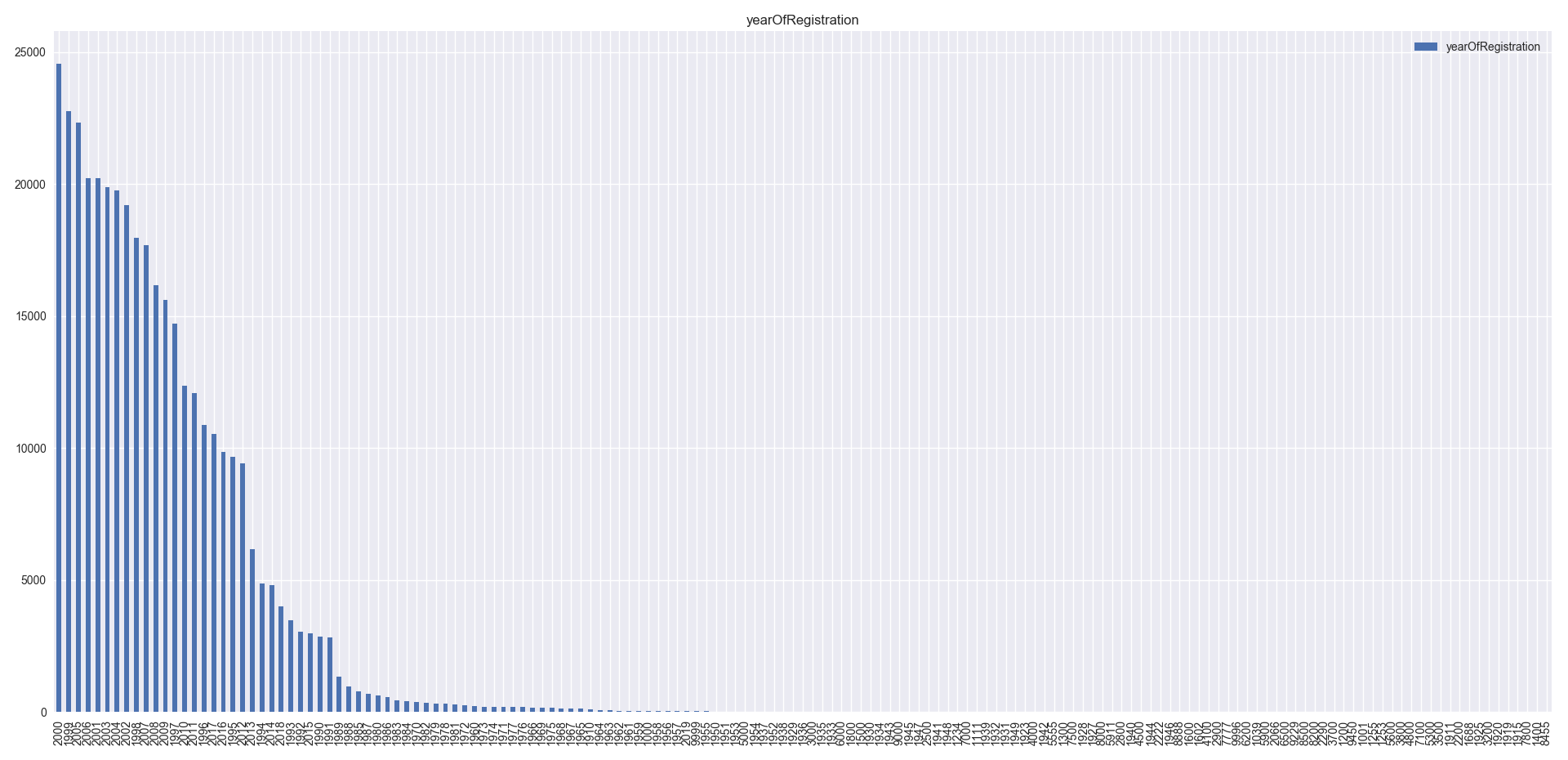
- Based on histogram of yearsOfRegistration column and its description result, this column has inconsistent values. For example, it has year values larger than 2017. Also, there are some values smaller than 1900 which does not make sense because in that time engine did not invented. So, yersOfRegistration records can be limited between 1900- yearsOfRegistration-2017.
- Based on histogram of powerPS and Table 1, this column has some inconsistent values. powerPS can’t be less than 0. Also, powerPS can’t be stronger than 1000. So, it can be limited between 0-powerPS-1000. Other records can be removed from the dataset to have consistent values.
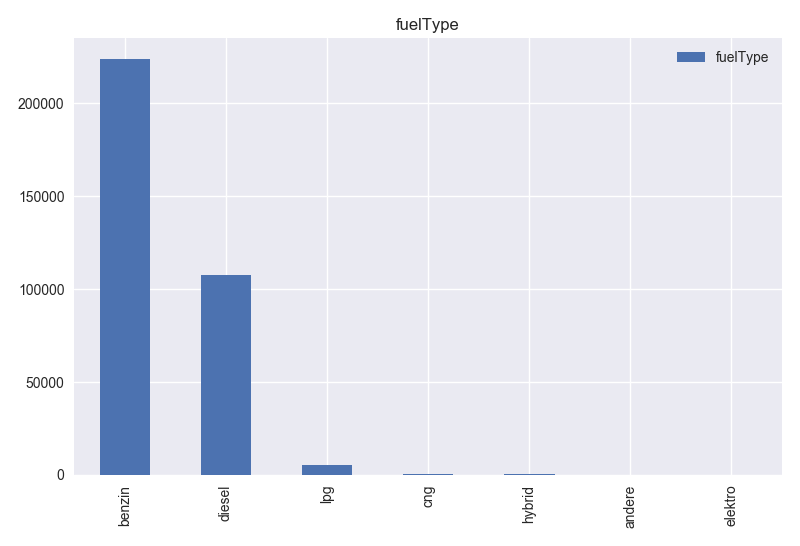
- Based on histogram of fuelType and Table 1, this column has 7 different value type. Apart from “benzin” and “diesel”, other values have very low records. So, these values do not mean much for the model. These records can be removed from the dataset.
- Based on vehicleType histogram and Table 1, it has 8 different values. Values are consistent and can be used for the model.
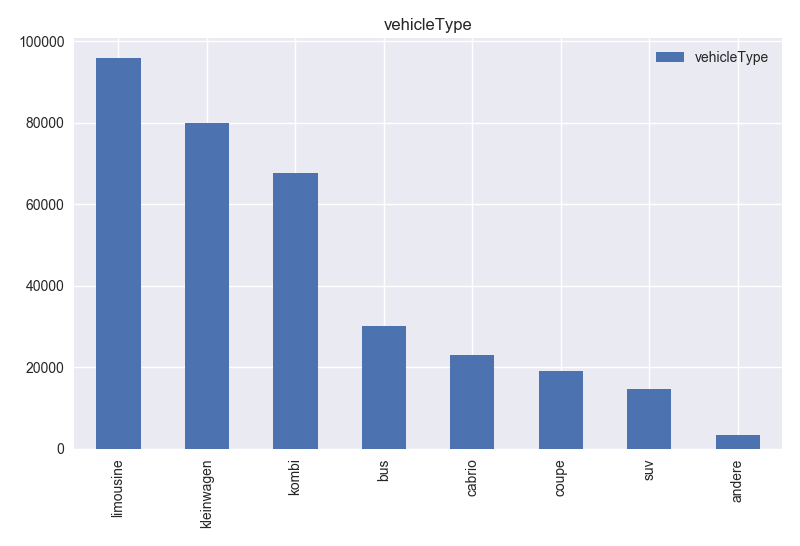
- Based on histogram of model and Table 1, this column has many different values. It can be useful for price prediction but to make the model simpler this column can be dropped.
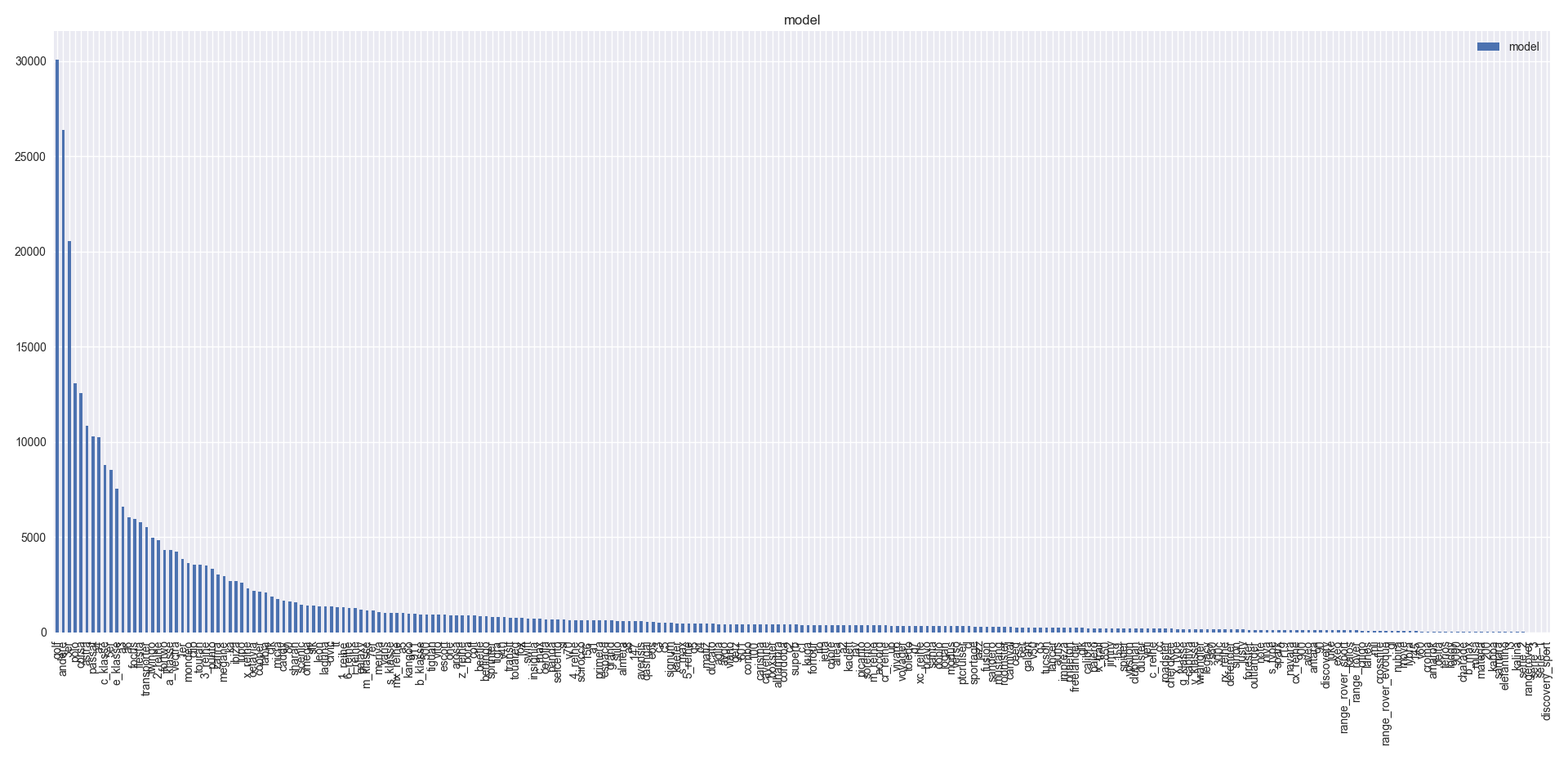
- Based on histogram of kilometer and table 1, this column has consistent values. Also, it can be useful for the model.
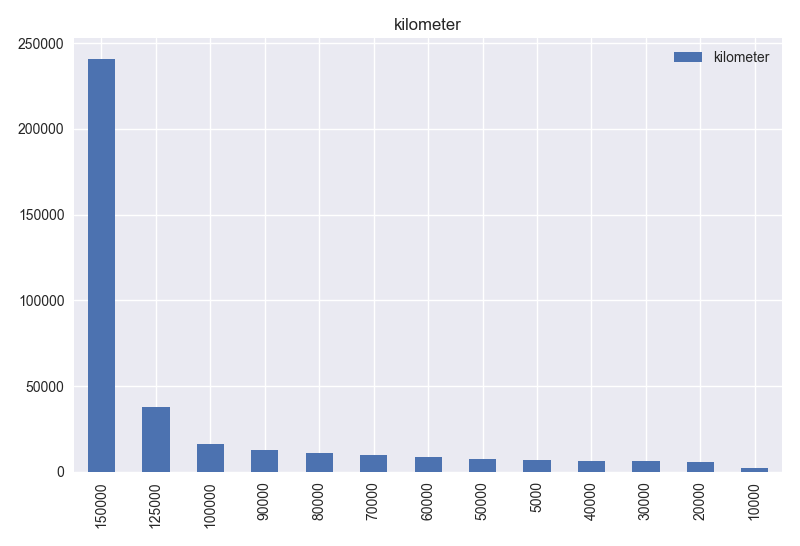
- Based on histogram of gearbox and Table 1, this column has 2 different values and values are consistent.
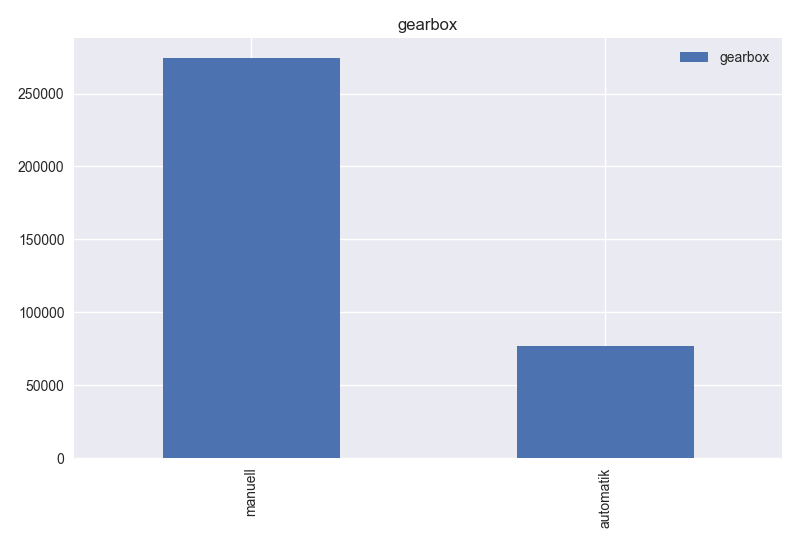
- Based on histogram of notRepairedDamage, this column has 2 different values. Values are consistent and can be useful for the model.
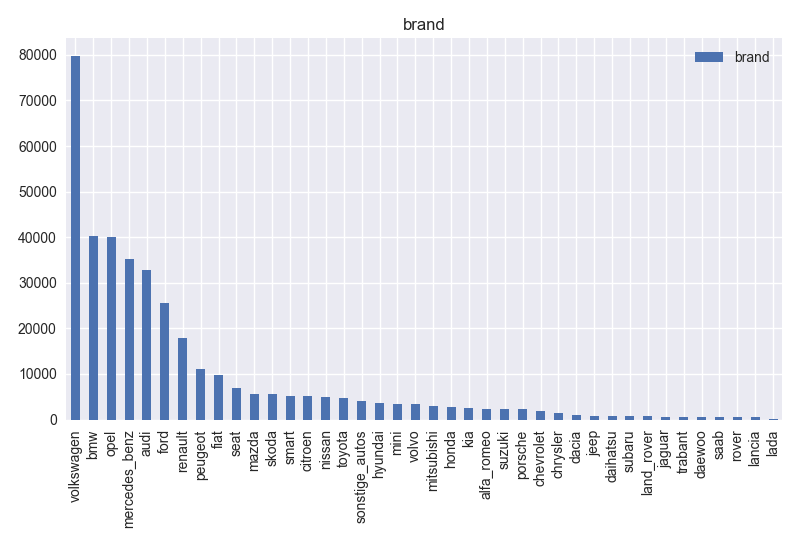
- Based on histogram of the brand, this column has 40 different values. It has consistent records and can be useful for the model. Also, it can be said that volkswagen is the most popular car.
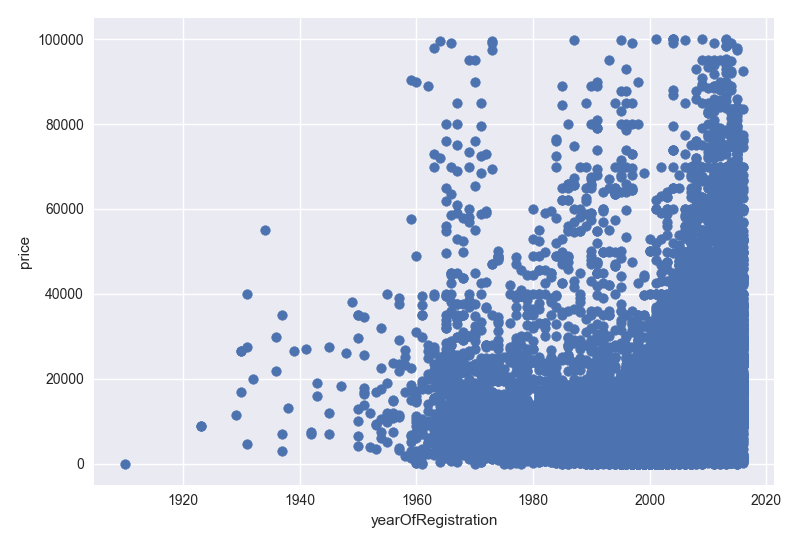
- Based on year v.s. price graph, it can be said that new cars are more expensive than old ones. However, there some old cars which are also expensive.
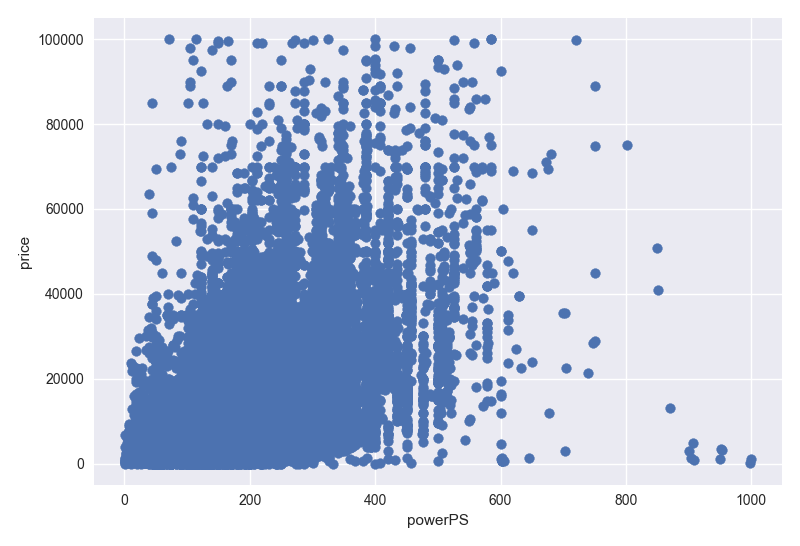
- Based on powerPS v.s price graph, low powerPS cars are cheaper than others.
3. PROBLEM SETTING
The problem is predicting the actual price of the car by looking given parameters.
There are 371528 records in dataset. 243422
of them are remaining after data cleaning process.
2 models are implemented.
One of them uses the 30% of the dataset as a test set.
Other one uses 33% for testing issue
4. MODELLING
Before the implementation of the model. Dataset is cleaned using python libraries, and total number of column is decreased to 10 ['vehicleType', 'yearOfRegistration', 'gearbox', 'powerPS', 'model','kilometer', 'fuelType', 'brand', 'notRepairedDamage', 'price'].
After that, cleaned dataset is preprocessed using WEKA. WEKA attribute evaluator selected some attributes. It suggests the following attributes for the model ['yearOfRegistration', 'gearbox', 'powerPS' ,'kilometer', 'fuelType', 'notRepairedDamage].
There are 2 different implementation of linear regression model:
- First model is implemented using python sklearn library. It has 10 attributes.
- Second model is implemented using WEKA. Attributeselection filter of WEKA applied on the dataset.
30 percentage of the dataset is used for testing.
Filter removed the 3 attributes. Remaining 7 attributes are used for learning.
33 percentage of the dataset is used for testing.
5. CONCLUSION and IMPROVEMENT POINTS
First 20 prediction of the both model is on the below table.
Python Sklearn Regression model has lower error than the WEKA model.
It gives pretty good result for such a simple model.
In order to improve the model:
- dataset cleaning could be more effienct. According to histogram graph of the attributes, they have lots of
inconsistent values.
- age of the car attribute can improve the model. Age attribute could be extracted
by using registrationDate and dateCreated attributes.
- according to attributeselection filter of the WEKA, "kilometer" and "powerPS" attributes are the most important ones.
Following results are taken from python sklearn model:
Root mean squared error: 555.6768635632562mean_absulute_error: 397.8973442835626
mean_squared_error: 308776.7766994987
Following results are taken from WEKA model:
Root mean squared error:4958.1553Mean absolute error: 3103.1781
Correlation coefficient: 0.7864
Relative absolute error: 56.7852 %
Root relative squared error: 61.7716 %
Total Number of Instances: 82763
PYTHON SKLEARN LINEAR REGRESSION MODEL RESULT
Root mean squared error: 555.6768635632562
| inst# | actual | predicted | error |
| 1 | 400 | 419.435 | 19.435 |
| 2 | 400 | 602.408 | 202.408 |
| 3 | 624 | 955.720 | 331.720 |
| 4 | 2579 | 1690.700 | 888.299 |
| 5 | 2166 | 1737.427 | 428.572 |
| 6 | 1697 | 2051.277 | 354.277 |
| 7 | 835 | 839.545 | 4.545 |
| 8 | 3062 | 2340.980 | 721.019 |
| 9 | 2273 | 1970.432 | 302.567 |
| 10 | 897 | 1485.134 | 588.134 |
| 11 | 2006 | 2126.953 | 120.953 |
| 12 | 1225 | 1281.999 | 56.999 |
| 13 | 1149 | 695.919 | 453.080 |
| 14 | 1863 | 1228.076 | 634.923 |
| 15 | 3352 | 2866.412 | 485.587 |
| 16 | 2056 | 1947.652 | 108.347 |
| 17 | 0 | 664.973 | 664.973 |
| 18 | 1975 | 1852.990 | 122.009 |
| 19 | 932 | 868.003 | 63.996 |
| 20 | 3435 | 2710.145 | 724.854 |
WEKA MODEL RESULT
Root mean squared error: 4958.1553
| inst# | actual | predicted | error |
| 1 | 9499 | 5840.168 | -3658.832 |
| 2 | 7990 | 12515.27 | 4525.27 |
| 3 | 4000 | 5139.611 | 1139.611 |
| 4 | 10700 | 14125.198 | 3425.198 |
| 5 | 690 | -3346.537 | -4036.537 |
| 6 | 1450 | 3834.998 | 2384.998 |
| 7 | 1000 | 720.987 | -279.013 |
| 8 | 7800 | 5329.186 | -2470.814 |
| 9 | 8150 | 8553.781 | 403.781 |
| 10 | 1111 | 720.987 | -390.013 |
| 11 | 9899 | 16116.077 | 6217.077 |
| 12 | 150 | -4427.849 | -4577.849 |
| 13 | 2000 | 5802.808 | 3802.808 |
| 14 | 15000 | 11530.067 | -3469.933 |
| 15 | 8000 | 10208.546 | 2208.546 |
| 16 | 4190 | 4656.816 | 466.816 |
| 17 | 16000 | 20750.782 | 4750.782 |
| 18 | 6000 | 7567.218 | 1567.218 |
| 19 | 2800 | 4278.547 | 1478.547 |
| 20 | 399 | 1198.466 | 799.466 |